Elasticsearch 基础
Elasticsearch 服务安装
Windows
1. 下载 Elasticsearch 安装包
访问Elasticsearch 官网,本次使用8.14.3版本。下载后将 ZIP 解压到一个没有中文和空格的目录,例如D:\SoftWare\elasticsearch-8.14.3,这个目录称为ES_HOME。
| 路径 | 作用详解 |
|---|---|
bin/ | 核心执行脚本目录。 • elasticsearch.bat: 启动 Elasticsearch 服务的主脚本。• elasticsearch-service.bat: 将 Elasticsearch 注册为系统服务的管理脚本(可选)。 • elasticsearch-inventory.bat: 查看已安装的插件和版本信息。 • elasticsearch-plugin.bat: 管理插件(安装、卸载、列出)的命令行工具。 • elasticsearch-sql-cli.bat: SQL 查询客户端(需单独安装插件)。 • elasticsearch-users.bat: 管理内置用户(如 elastic)的命令行工具。 |
config/ | 配置文件目录,存放所有核心配置。 • elasticsearch.yml: 最重要的配置文件,用于设置集群名称、节点名称、网络、数据路径等。• jvm.options: JVM 启动参数配置文件,控制堆内存大小、GC 策略等。• log4j2.properties: 日志框架配置文件。 |
jdk/ | 内置的 JDK 22 运行环境。7.x以后特有,自带的 java 环境 |
lib/ | 依赖库目录。 • 包含 Elasticsearch 运行所需的所有 Java JAR 包。 |
logs/ | 默认的日志输出目录。 • 存放 elasticsearch.log、gc.log 等日志文件。 |
modules/ | 核心模块目录。 • 包含 Elasticsearch 的核心功能模块,如安全、机器学习、监控等。 |
plugins/ | 插件目录。 • 存放所有已安装的第三方或官方插件。 |
LICENSE.txt | 软件许可证文件。包含 Apache License 2.0 许可证全文。 |
NOTICE.txt | 版权与声明文件。包含第三方组件的版权声明和说明。 |
README.asciidoc | 官方文档入口。 • 提供快速入门指南、配置示例和重要注意事项。 |
2.配置 JDK 环境变量
配置ES_JAVA_HOME与ES_HOME环境变量。
ES_JAVA_HOME:用于指定 Elasticsearch 使用的 Java 运行时环境的路径。
ES_HOME:指定 Elasticsearch 的安装路径。它用于定位 Elasticsearch 的配置文件、插件和其它相关资源。
- 右键「此电脑」→「属性」
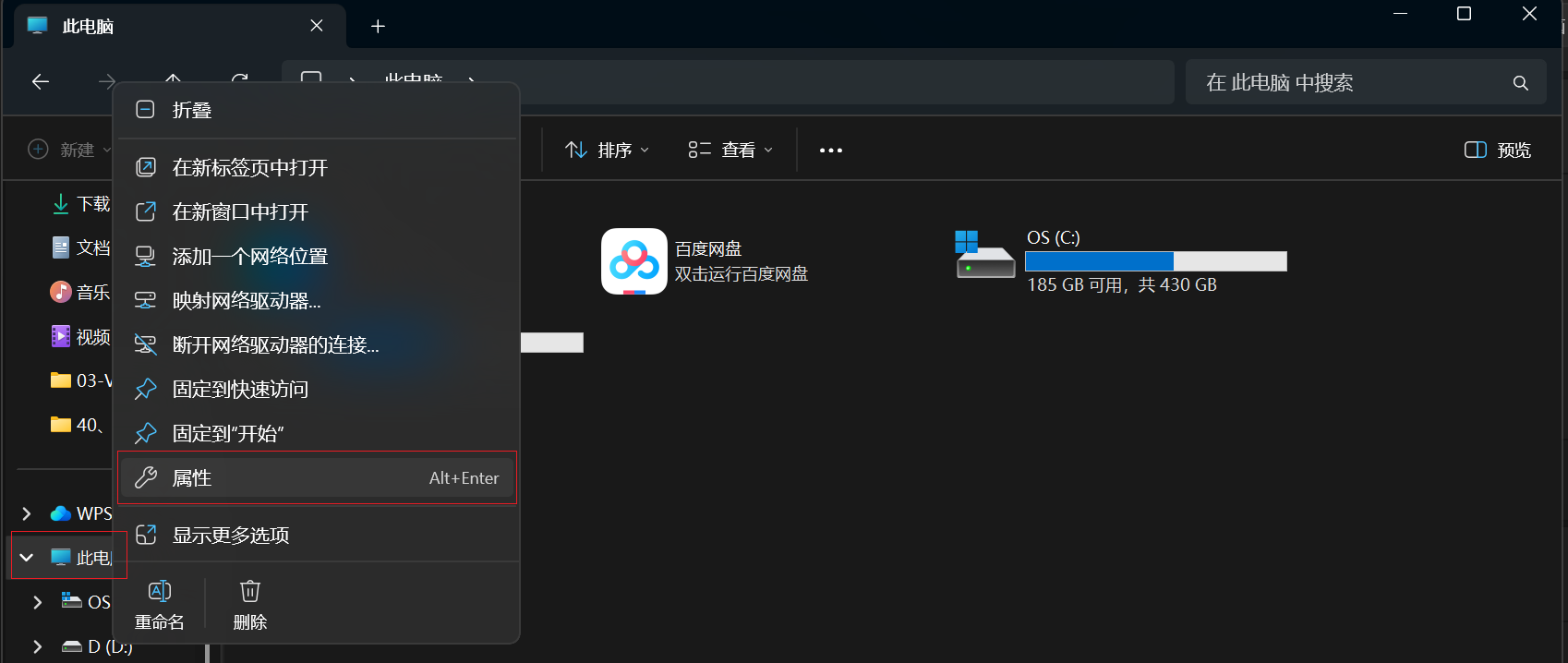
- 「高级系统设置」
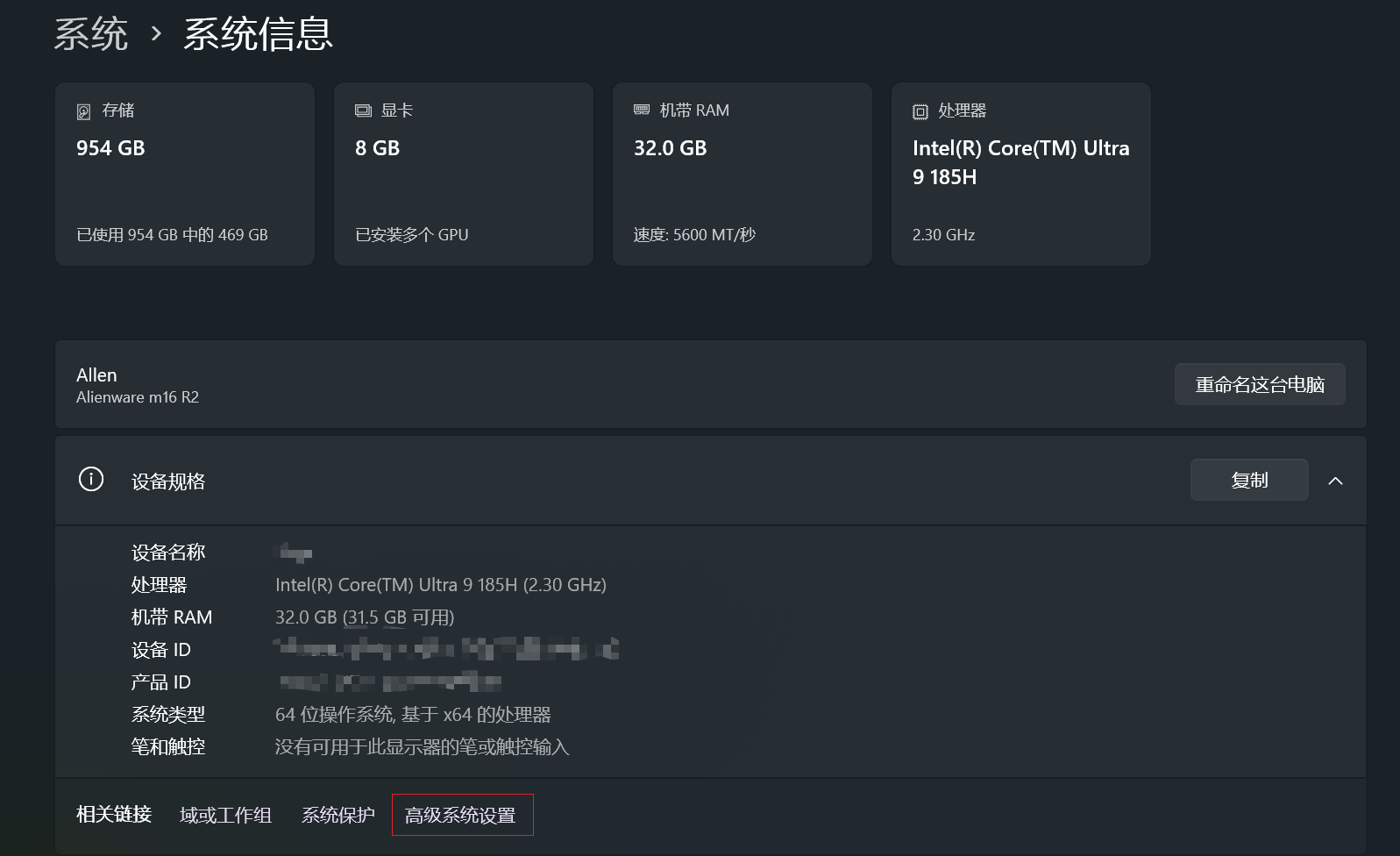
- 「环境变量」
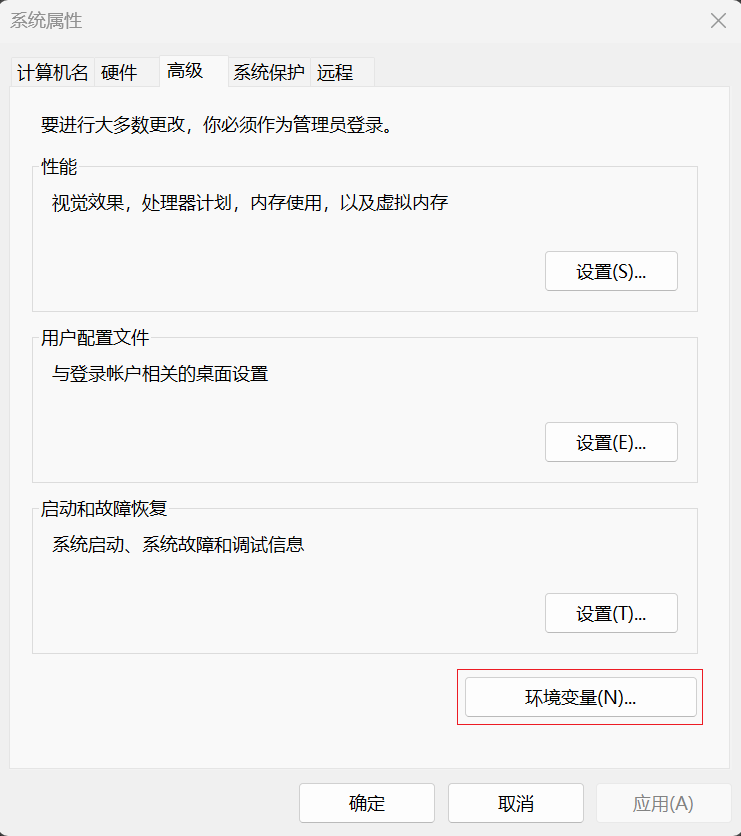
系统变量区域,点击「新建」,添加 ES_JAVA_HOME 和 ES_HOME 环境变量:
- 变量名:
ES_HOME,变量值:Elasticsearch 安装路径(如D:\SoftWare\elasticsearch-8.14.3)。 - 变量名:
ES_JAVA_HOME,变量值:用于指定 Elasticsearch 使用的 Java 运行时环境的路径。建议设置为 Elasticsearch 自带的 jdk 路径(如D:\SoftWare\elasticsearch-8.14.3\jdk)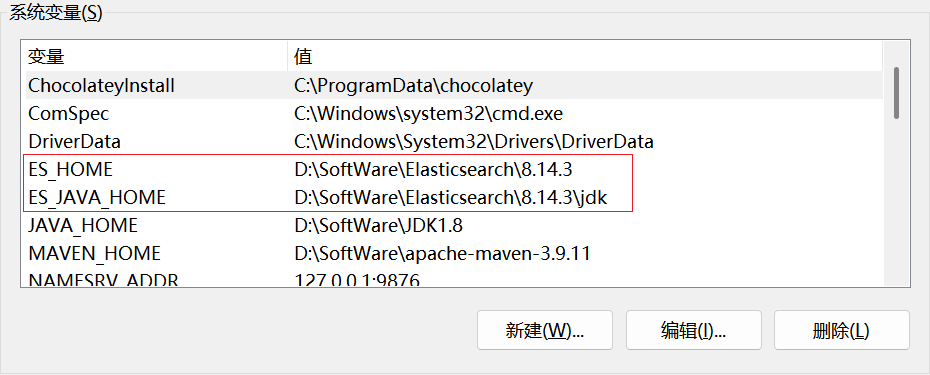
警告
- Elasticsearch 比较耗内存,建议虚拟机 4G 或以上内存,JVM 1G 以上的内存分配。
- 运行 Elasticsearch,需安装并配置JDK。各个版本的对 Java 依赖的版本是不同的。8.14.3 版本需要 JDK17 或 JDK21 及以上版本。
- Elasticsearch
环境变量生效的优先级配置顺序 ES_JAVA_HOME > JAVA_HOME。
3. 修改配置文件
Elasticsearch8 默认是开启 Security 认证的,为了便于快速上手,可以关闭 Security。
编辑config/elasticsearch.yml文件,在文件头部添加xpack.security.enabled: false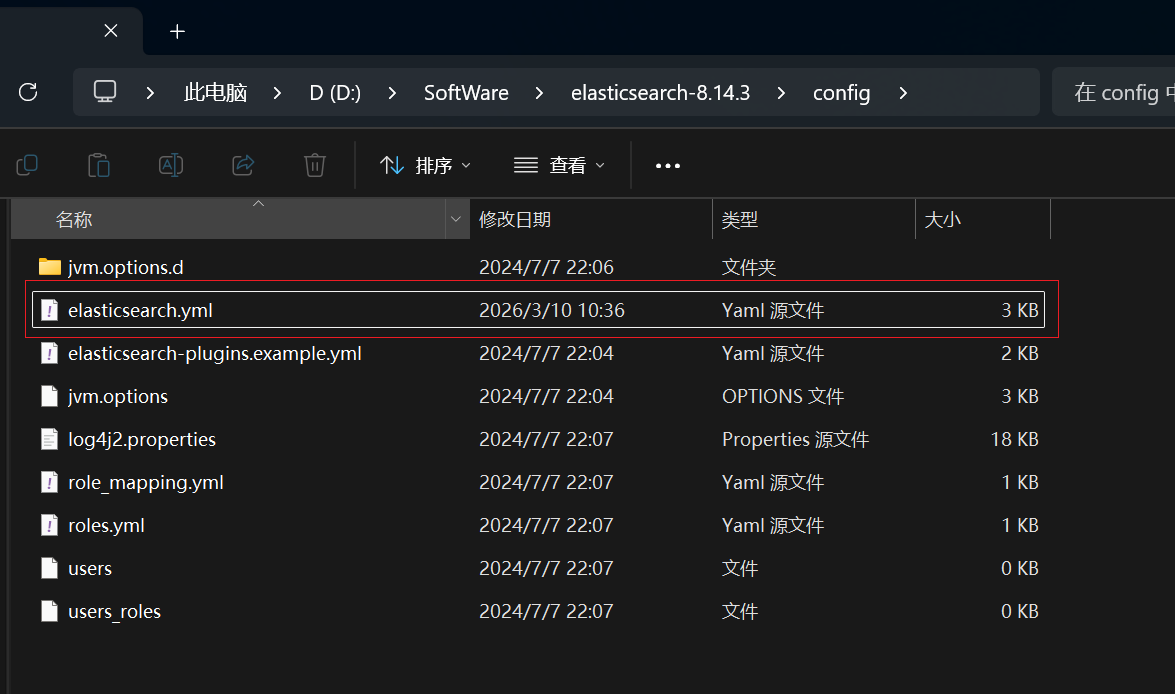
4. 启动 Elasticsearch
- 进入
bin目录,点击elasticsearch.bat文件启动 ES 服务。
端口注意
注意:9300端口为 Elasticsearch 集群间组件的通信端口,9200端口为浏览器访问的 Http 协议 Restful 端口。
- 打开浏览器(推荐使用谷歌浏览器),输入地址:
http://localhost:9200,测试结果。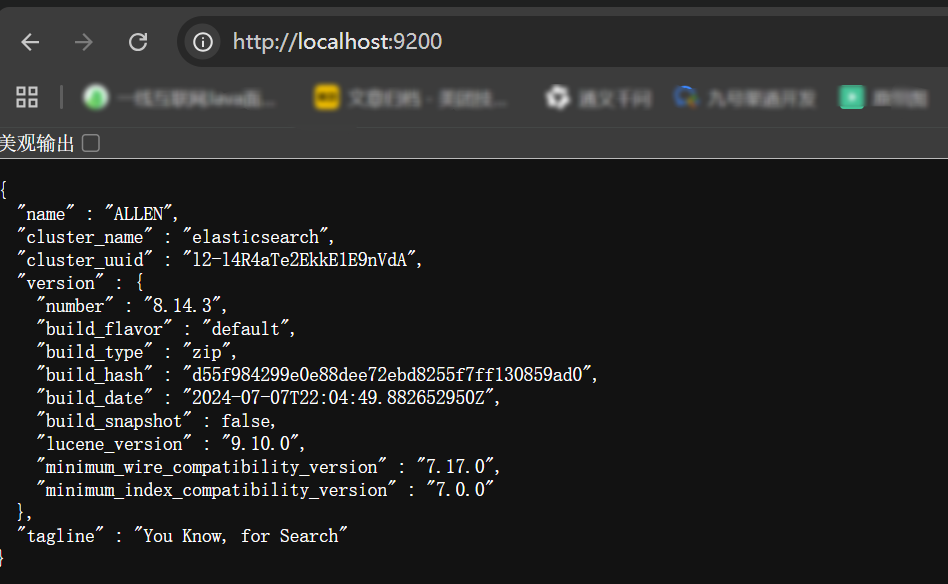
Linux
Elasticsearch 服务安装
1. 下载
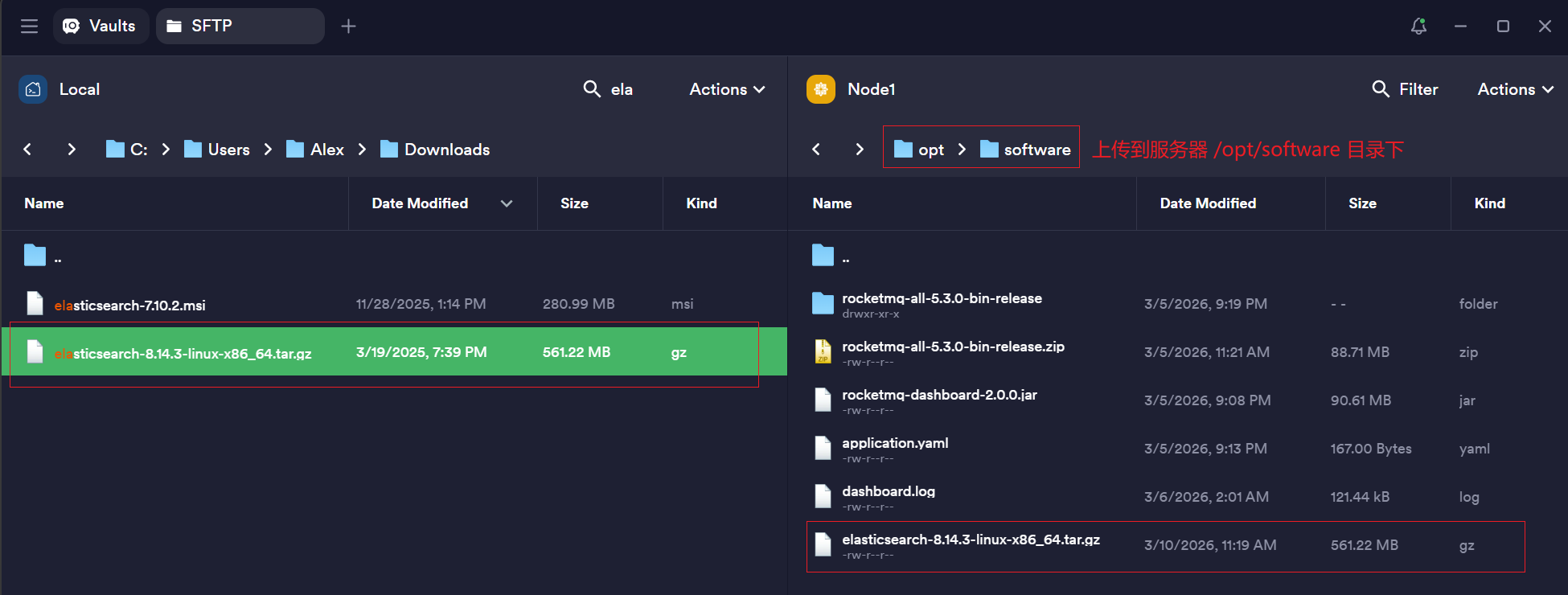
方式一: 官网下载并上传(推荐)
- 官网下载页 选择最新版本的二进制包下载
- 通过 SFTP 上传到服务器
方式二: 使用 wget 命令直接下载(不推荐,非国内网站,下载过慢)
# 新建并进入指定目录 (如果目录已存在则不会删除并新建, 会保留)
mkdir -p /opt/software
cd /opt/software/
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.14.3-linux-x86_64.tar.gz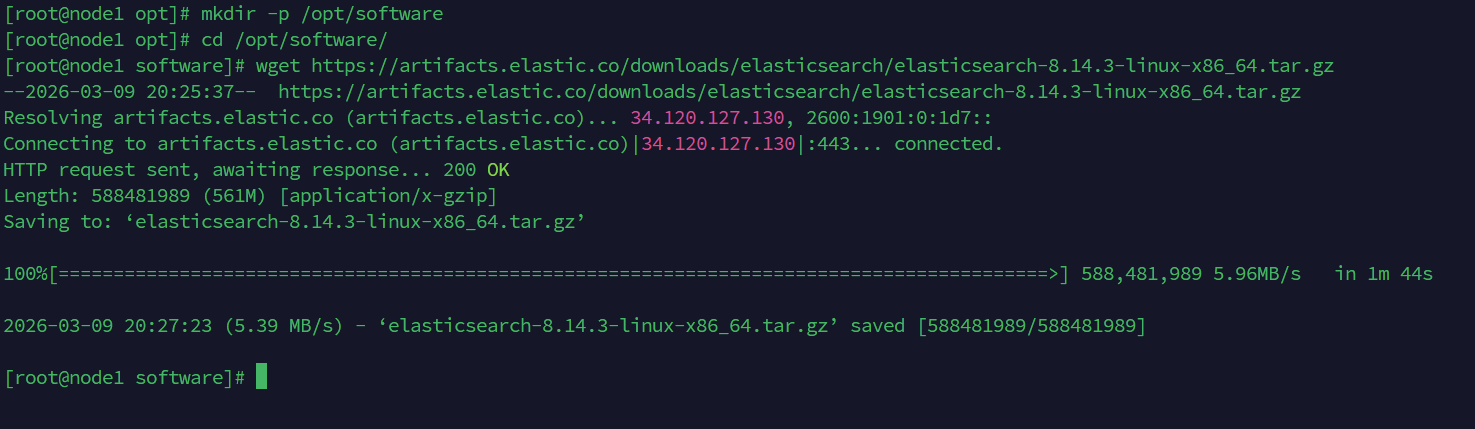
2. 解压
cd /opt/software/
# 解压 elasticsearch-8.14.3-linux-x86_64.tar.gz 压缩包
tar -zxvf elasticsearch-8.14.3-linux-x86_64.tar.gz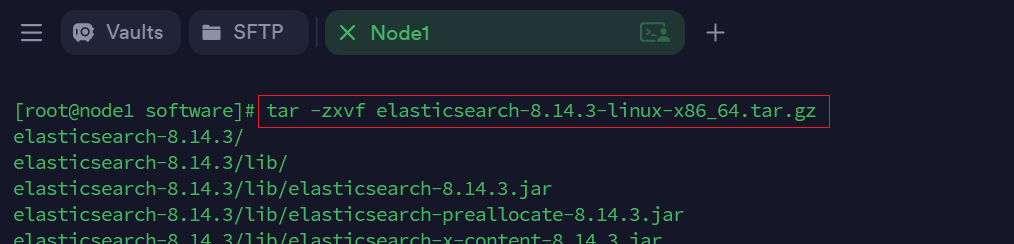

3. 配置 JDK 环境变量
配置ES_JAVA_HOME与ES_HOME环境变量。
ES_JAVA_HOME:用于指定 Elasticsearch 使用的 Java 运行时环境的路径。
ES_HOME:指定 Elasticsearch 的安装路径。它用于定位 Elasticsearch 的配置文件、插件和其它相关资源。
# 进入 用户主目录,比如 /home/elastic 目录下,设置用户级别的环境变量
cd /home/elastic
vim .bash_profile
# 设置 ES_JAVA_HOME 和 ES_HOME 路径
export ES_JAVA_HOME=/opt/software/elasticsearch-8.14.3/jdk
export ES_HOME=/opt/software/elasticsearch-8.14.3
# 执行命令使配置生效
source .bash_profile警告
- Elasticsearch 比较耗内存,建议虚拟机 4G 或以上内存,JVM 1G 以上的内存分配。
- 运行 Elasticsearch,需安装并配置JDK。各个版本的对 Java 依赖的版本是不同的。8.14.3 版本需要 JDK17 或 JDK21 及以上版本。
- Elasticsearch
环境变量生效的优先级配置顺序 ES_JAVA_HOME > JAVA_HOME。
4. 修改配置文件
- 修改
config/elasticsearch.yml配置文件
vim elasticsearch.yml
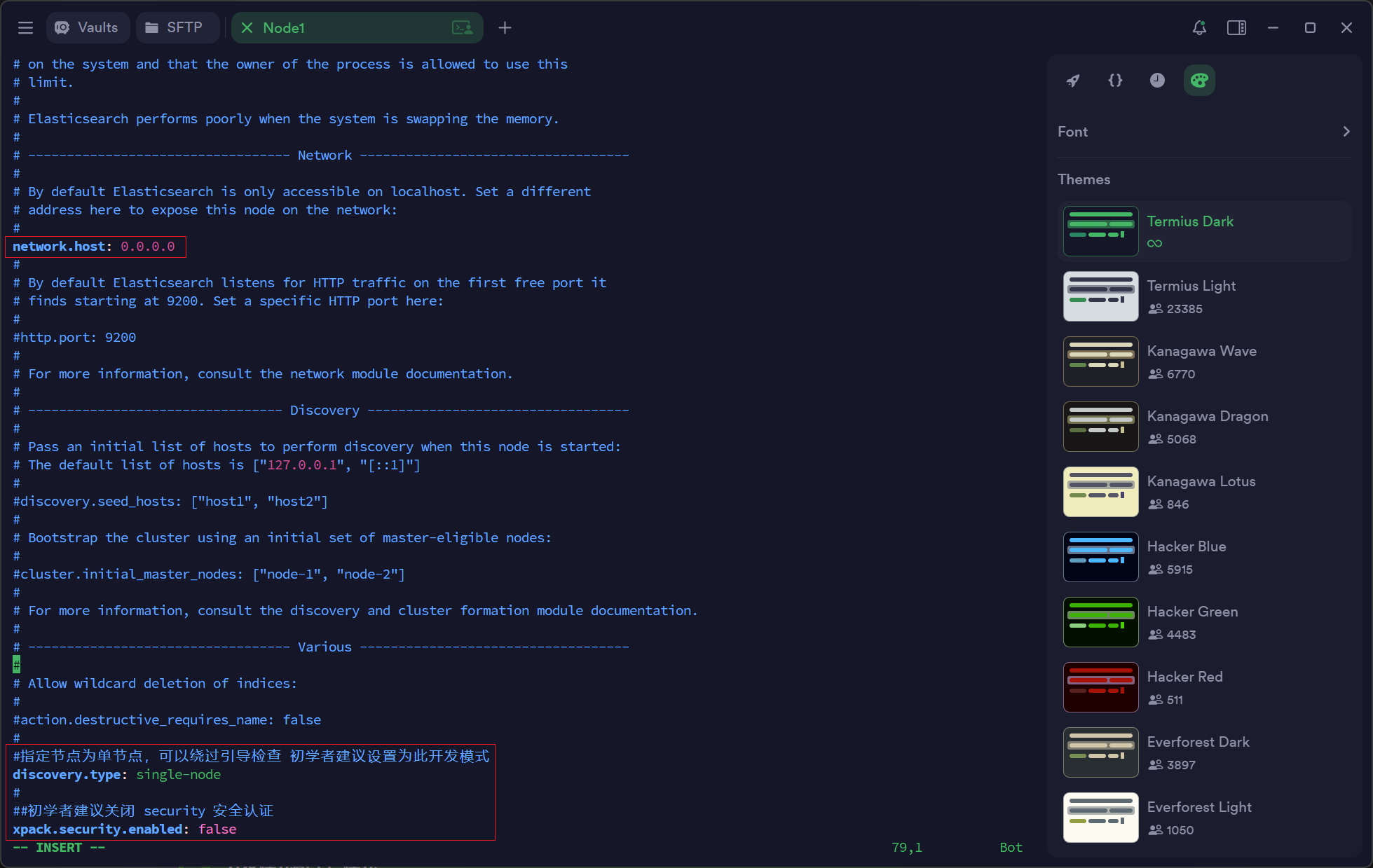
# 节点对外提供服务的地址以及集群内通信的 ip 地址,默认值为当前节点所在机器的本机回环地址127.0.0.1 和[::1],这就导致默认情况下只能通过当前节点所在主机访问当前节点。
#配置为 0.0.0.0 开启远程访问支持
network.host: 0.0.0.0
#指定节点为单节点,可以绕过引导检查 初学者建议设置为此开发模式
discovery.type: single-node
#初学者建议关闭security安全认证
xpack.security.enabled: false
Elasticsearch 常用参数配置参考文档
开发模式和生产模式
开发模式:开发模式是默认配置(未配置集群发现设置),如果用户只是出于学习目的,而引导检查会把很多用户挡在门外,所以 ES 提供了一个设置项discovery.type=single-node。此项配置为指定节点为单节点,可以绕过引导检查。
生产模式:当用户修改了有关集群的相关配置会触发生产模式,在生产模式下,服务启动会触发 ES 的引导检查或者叫启动检查(bootstrap checks),所谓引导检查就是在服务启动之前对一些重要的配置项进行检查,检查其配置值是否是合理的。引导检查包括对 JVM 大小、内存锁、虚拟内存、最大线程数、集群发现相关配置等相关的检查,如果某一项或者几项的配置不合理,ES 会拒绝启动服务,并且在开发模式下的某些警告信息会升级成错误信息输出。引导检查十分严格,之所以宁可拒绝服务也要阻止用户启动服务是为了防止用户在对 ES 的基本使用不了解的前提下启动服务而导致的后期性能问题无法解决或者解决起来很麻烦。因为一旦服务以某种不合理的配置 启动,时间久了之后可能会产生较大的性能问题,但此时集群已经变得难以维护和扩展,ES 为了避免这种情况而做出了引导检查的设置,本来在开发模式下为警告的启动日志会升级为报错(Error)。这种设定虽然增加了用户的使用门槛,但是避免了日后产生更大的问题。
- 修改
config/jvm.options配置文件,调整 jvm 堆内存大小(可选)
vim jvm.options
-Xms 2g
-Xmx 2g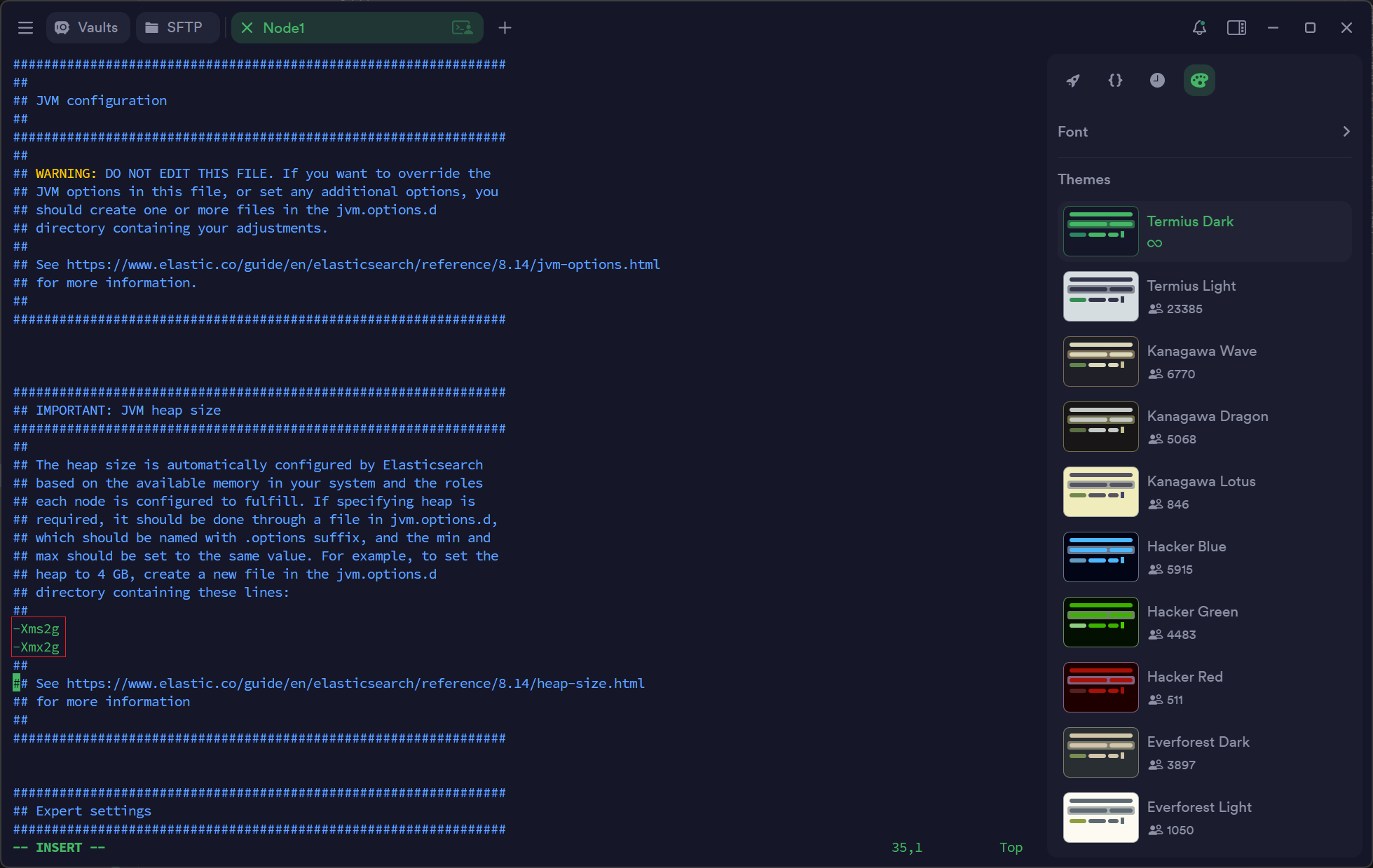
| 参数 | 含义 | 详细解释 |
|---|---|---|
Xms | Initial Heap Size (初始堆大小) | 指定 JVM 启动时为堆内存分配的初始容量。这个值是程序运行开始时堆内存的“起点”。 ✅ 作用:减少启动时的内存分配压力,避免频繁的内存扩展。 |
Xmx | Maximum Heap Size (最大堆大小) | 指定 JVM 堆内存能够增长到的最大容量。这是堆内存的上限。 ✅ 作用:防止应用程序因内存耗尽而崩溃(OOM - Out Of Memory)。 |
配置建议
Xms(JVM 启动时分配的最小堆内存)和Xmx(JVM 在运行过程中能够分配的最大堆内存)设置成一样
Xmx不要超过机器内存的50%
5. 启动 Elasticsearch 服务
- 进入
bin目录,点击elasticsearch.bat文件启动 ES 服务。
# 进入 Elasticsearch 安装目录, 比如 /opt/software/elasticsearch-8.14.3
cd /opt/software/elasticsearch-8.14.3
# -d 后台启动
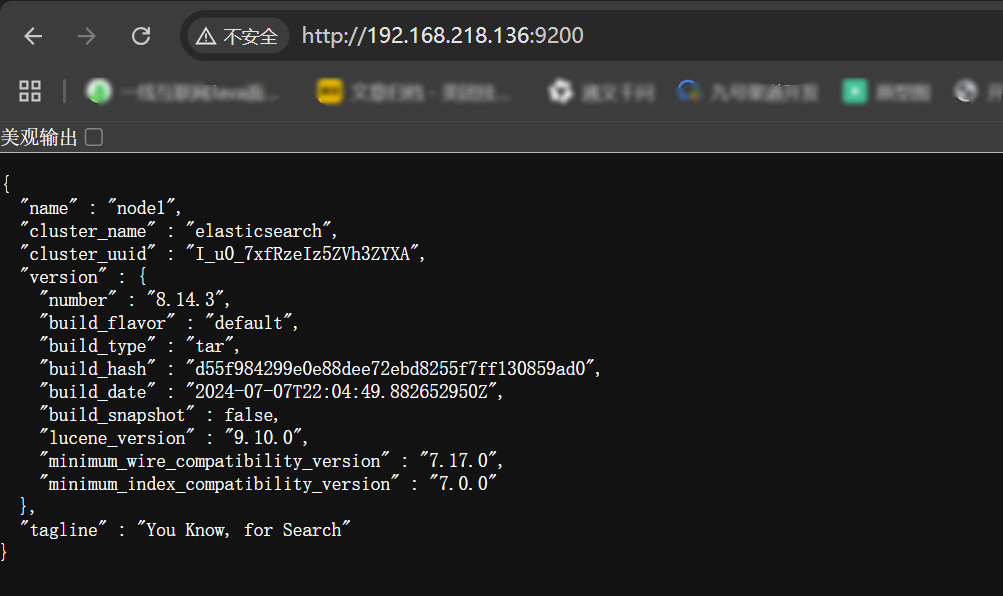
bin/elasticsearch -d- 打开浏览器(推荐使用谷歌浏览器),输入地址:
http://192.168.136:9200(IP 根据服务器实际 IP 进行替换),测试结果。
端口注意
9200端口为浏览器访问的 Http 协议 Restful 端口,9300端口为 Elasticsearch 集群间组件的通信端口。
常见问题
root 用户启动服务失败
原因分析Elasticsearch 不允许使用 root 用户启动服务,如果当前账号是 root,则需要创建一个专有账户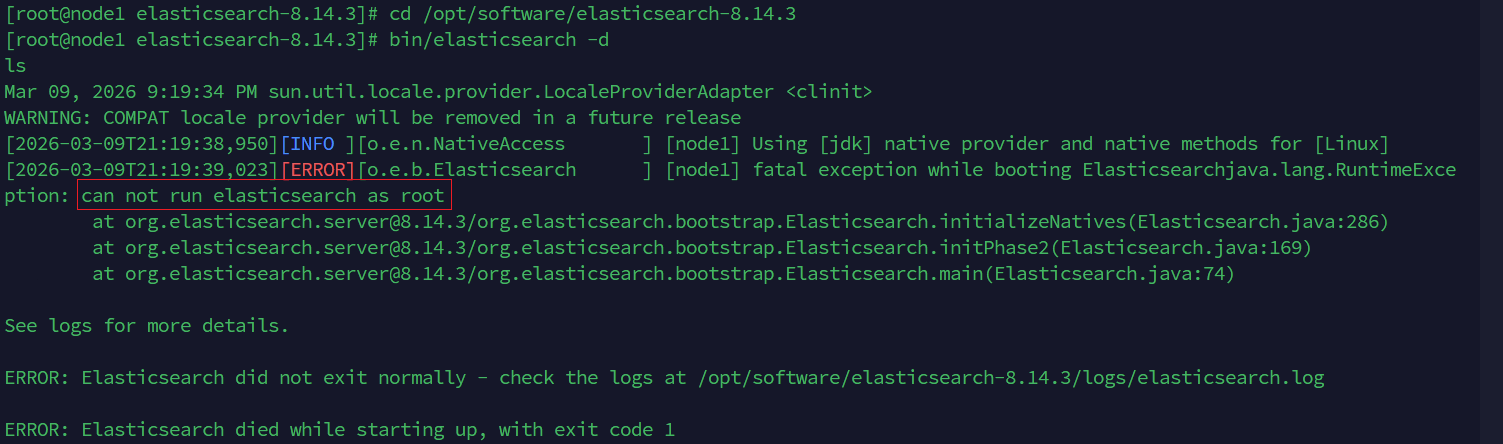
解决方案
- 为 elasticsearch 创建用户
adduser elastic
passwd elastic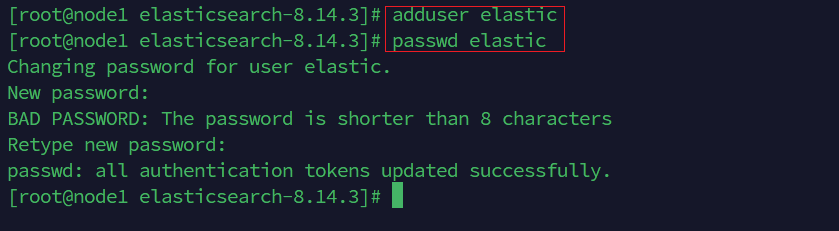
- 将 Elasticsearch 安装包的所有者和组更改为 elastic 用户
注意
如果在 root 下解压了 Elasticsearch 安装包,可以通过如下命令将 Elasticsearch 安装包的所有者和组更改为 elastic 用户
# 在 root 用户下操作
cd /opt/software
chown -R elastic:elastic elasticsearch-8.14.3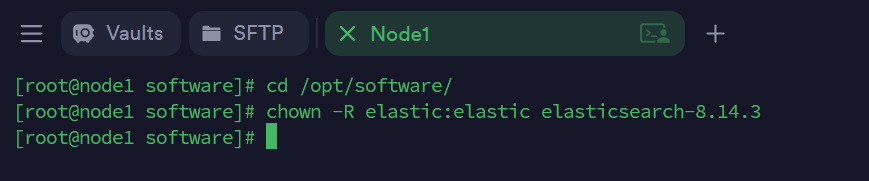
Windows 无法访问 ip:9200
原因分析
虚拟机 Linux 系统的防火墙未开放 Ellasticsearch 核心端口,导致网络请求被拦截。
解决方案一:开放 Linux 防火墙端口(推荐)
Elasticsearch 核心端口列表:
9200(TCP)- 浏览器访问的 Http 协议 Restful 端口
9300(TCP)- Elasticsearch 集群间组件的通信端口
# 开放核心端口
firewall-cmd --permanent --add-port=9200/tcp
firewall-cmd --permanent --add-port=9300/tcp
# 重新加载防火墙配置使修改生效
firewall-cmd --reload
# 验证端口是否开放成功
firewall-cmd --list-ports解决方案二:临时关闭防火墙(测试环境可选)
# CentOS/RHEL 系统
systemctl stop firewalld
systemctl disable firewalld
# Ubuntu/Debian 系统
ufw disable# Ubuntu/Debian 系统
ufw disableElasticsearch 客户端安装与使用(可选 推荐)
Elasticvue 安装
Elasticvue 浏览器插件安装
Elasticvue是一款 Elasticsearch 可视化管理插件。这些插件使得开发者能够通过图形界面轻松管理索引、查询数据、监控集群状态。
- 打开 Chrome Web Store。
- 搜索 "Elasticvue",点击 "添加至 Chrome"。
- 安装完成后,点击浏览器右上角的插件图标,在弹出的窗口中:
- 点击 "添加至ELASTICSEARCH集群"。
- 输入 Elasticsearch 地址,例如:
http://localhost:9200。 - (可选)如果启用了安全认证,填写用户名和密码。
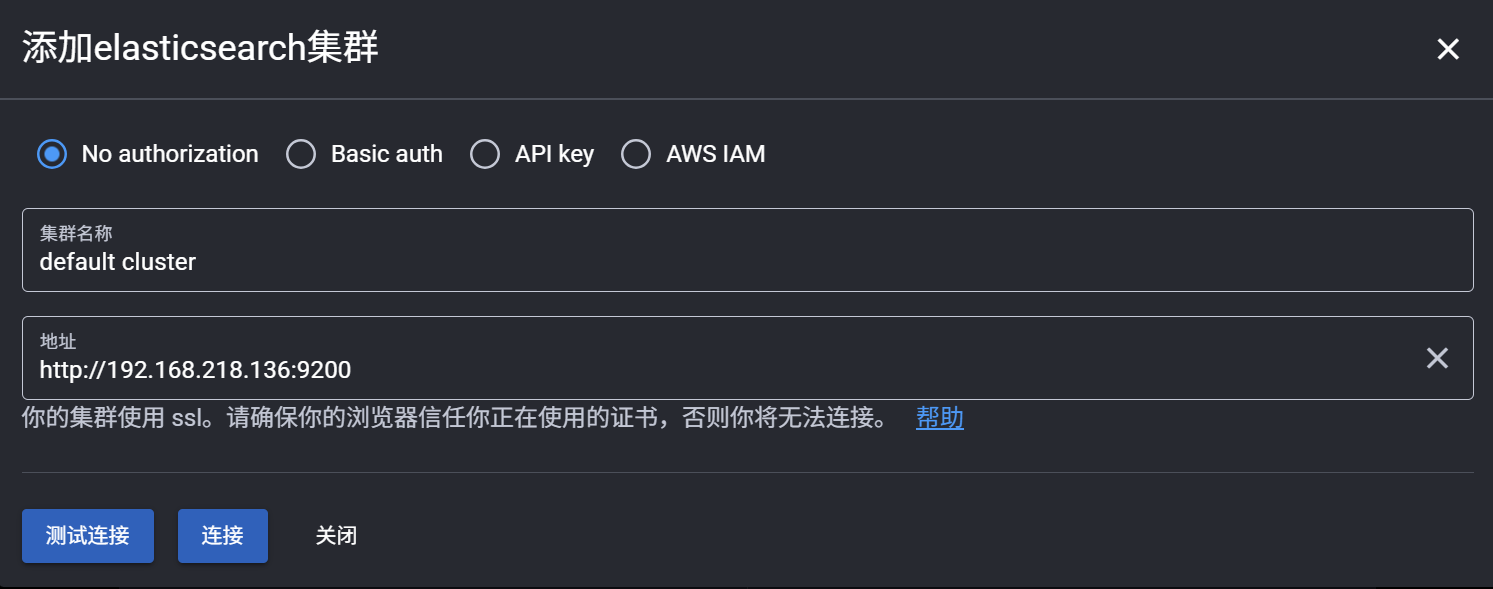
- 输入 Elasticsearch 地址,例如:
- 成功连接后,将看到一个功能丰富的界面,可以:
- 查看集群健康状态。
- 管理索引(创建、删除、查看映射)。
- 执行
GET、POST、PUT等 API 调用。 - 查看文档内容。
- 监控节点资源。
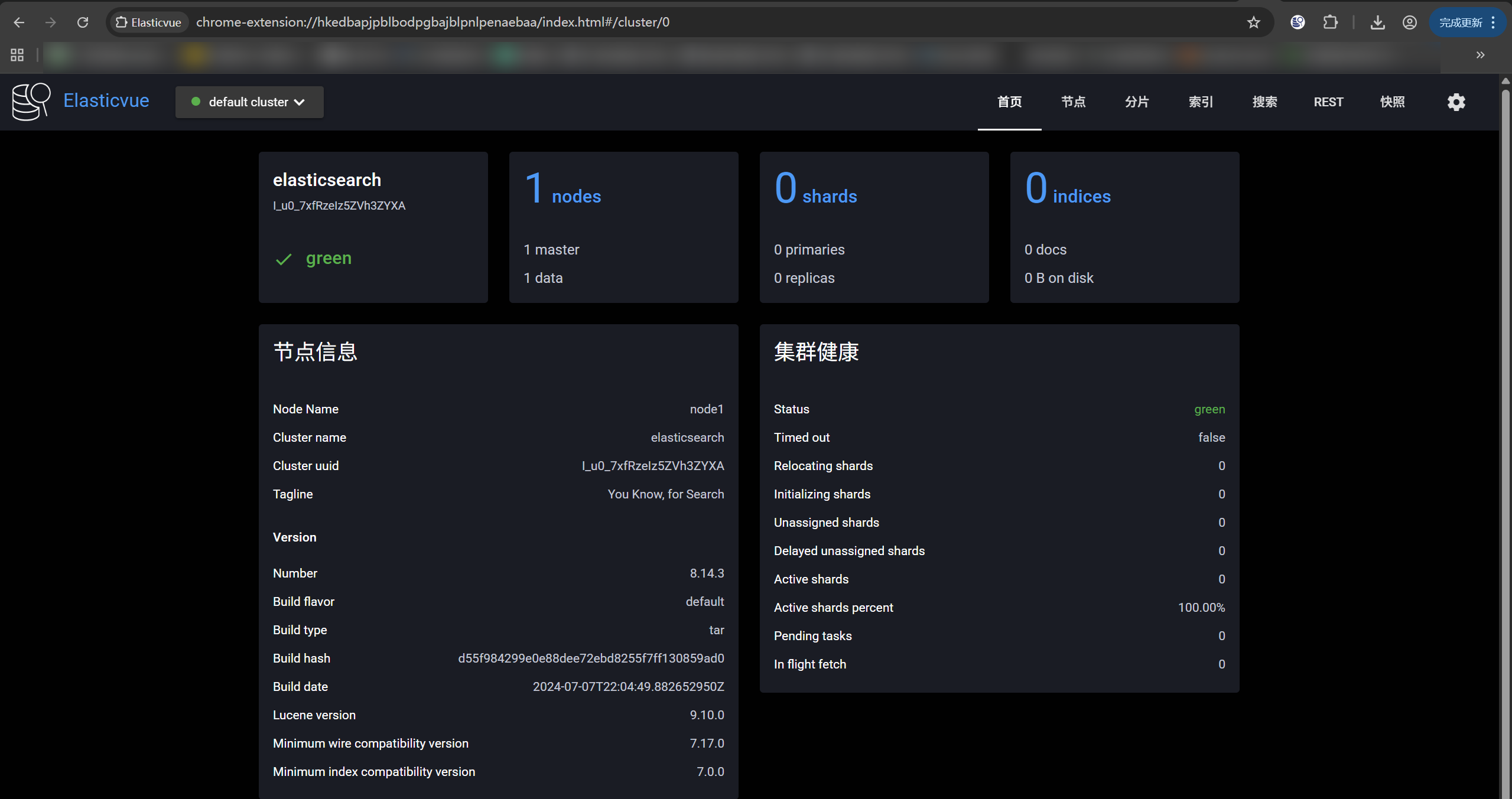
💡 优点:界面现代,支持 TLS/SSL,可管理多个集群,无需额外服务器。
如果插件无法正常下载, 也可直接安装 Elasticvue Windows 版应用。
Elasticvue Windows 版安装
访问Elasticvue官网下载 Windows 安装包 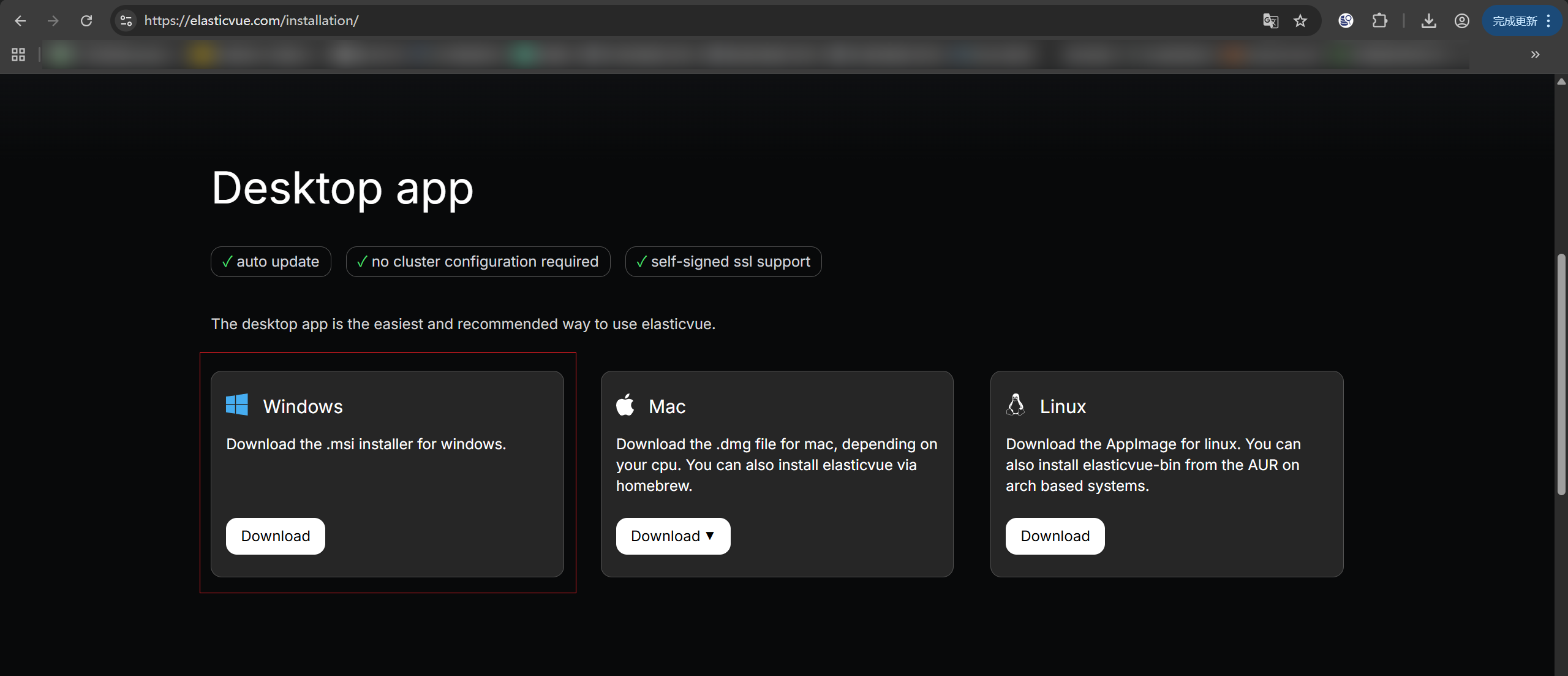
常见问题与解决
| 问题 | 解决方案 |
|---|---|
| 插件无法连接到 Elasticsearch | 1. 检查 Elasticsearch 是否运行。 2. 检查网络防火墙是否阻止了端口 9200。3. 检查 elasticsearch.yml 中是否设置了 network.host: 0.0.0.0,允许外部访问。 |
| 插件界面空白或报错 | 1. 尝试在无痕模式下打开。 2. 清除浏览器缓存。 3. 检查插件是否有更新。 |
其它
| 插件名称 | 推荐度 | 特点 | 官方链接 |
|---|---|---|---|
| Elasticvue | ⭐⭐⭐⭐⭐ | 功能强大,持续更新,最佳选择 | Chrome Web Store |
| ES Client | ⭐⭐⭐⭐☆ | 针对 Elasticsearch 的真实高频场景打造,从索引治理到运维自动化, 用一个纯客户端完成「感知-诊断-执行」的闭环 | Chrome Web Store |
| Elasticsearch Tools | ⭐⭐⭐⭐☆ | 简洁高效,适合快速操作 | Chrome Web Store |
| Elasticsearch Head | ⭐☆☆☆☆ | 已停止维护,不推荐 | GitHub (归档) |
💬 最终建议:优先使用
Elasticvue,它是当前最可靠、最现代化的 Elasticsearch 浏览器插件。
可视化客户端 Kibana 安装
Kibana 是一个开源分析和可视化平台,旨在与 Elasticsearch 协同工作。
1. 下载
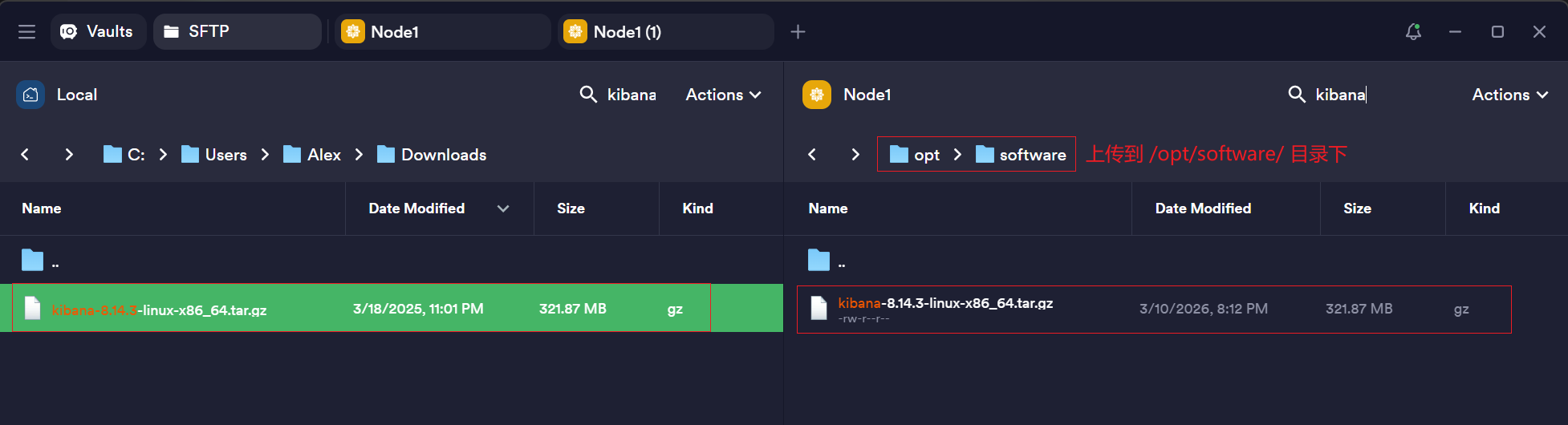
方式一: 官网下载并上传(推荐)
- 官网下载页 选择最新版本的安装包下载
- 通过 SFTP 上传到服务器
方式二: 使用 wget 命令直接下载(不推荐,非国内网站,下载过慢)
# 新建并进入指定目录 (如果目录已存在则不会删除并新建, 会保留)
mkdir -p /opt/software
cd /opt/software/
wget https://artifacts.elastic.co/downloads/kibana/kibana-8.14.3-linux-x86_64.tar.gz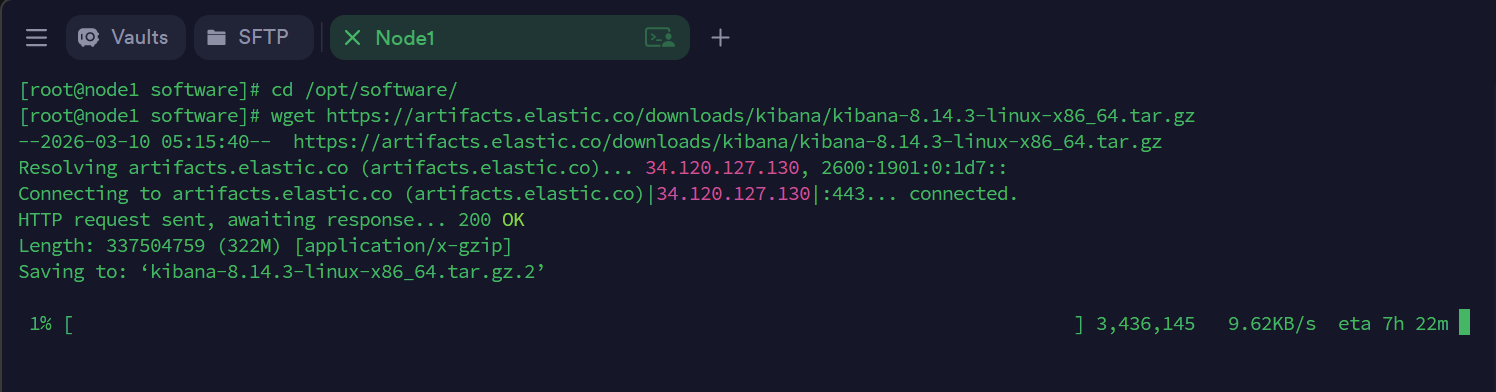
2. 解压
cd /opt/software/
# 解压 kibana-8.14.3-linux-x86_64.tar.gz 压缩包
tar -zxvf kibana-8.14.3-linux-x86_64.tar.gz3. 修改配置文件
cd /opt/software/kibana-8.14.3/
vim config/kibana.yml
# 指定 kinaba 服务器监听的端口号
server.port: 5601
# 指定 kibana 服务器绑定的主机地址
server.host: "0.0.0.0"
# 指定 kibana 连接到的 Elasticsearch 实例的访问地址, 根据虚拟机实际 IP 地址进行替换
elasticsearch.hosts: ["http://192.168.218.136:9200"]
# 将 kibana 的界面语言设置为简体中文
i18n.locale: "zh-CN"4. 启动 Kibana 服务
- 进入
bin目录,执行kibana脚本启动 Kibana 服务。
# 进入 Kibana 安装目录, 比如 /opt/software/kibana-8.14.3
cd /opt/software/kibana-8.14.3
# 后台启动,并将日志写入 logs/kibana.log
nohup bin/kibana > logs/kibana.log 2>&1 &
# 查询 kibana 进程
netstat -tunlp | grep 5601- 打开浏览器(推荐使用谷歌浏览器),输入地址:
http://192.168.136:5601(IP 根据服务器实际 IP 进行替换),测试结果。
端口注意
5601端口为浏览器访问的 Http 协议 Restful 端口。请确保端口已开放或服务器防火墙已关闭。
kibana 启动
kibana 服务不支持 root 用户启动。
常见问题
root 用户启动服务失败
原因分析Kibana 不允许使用 root 用户启动服务,如果当前账号是 root,则需要创建一个专有账户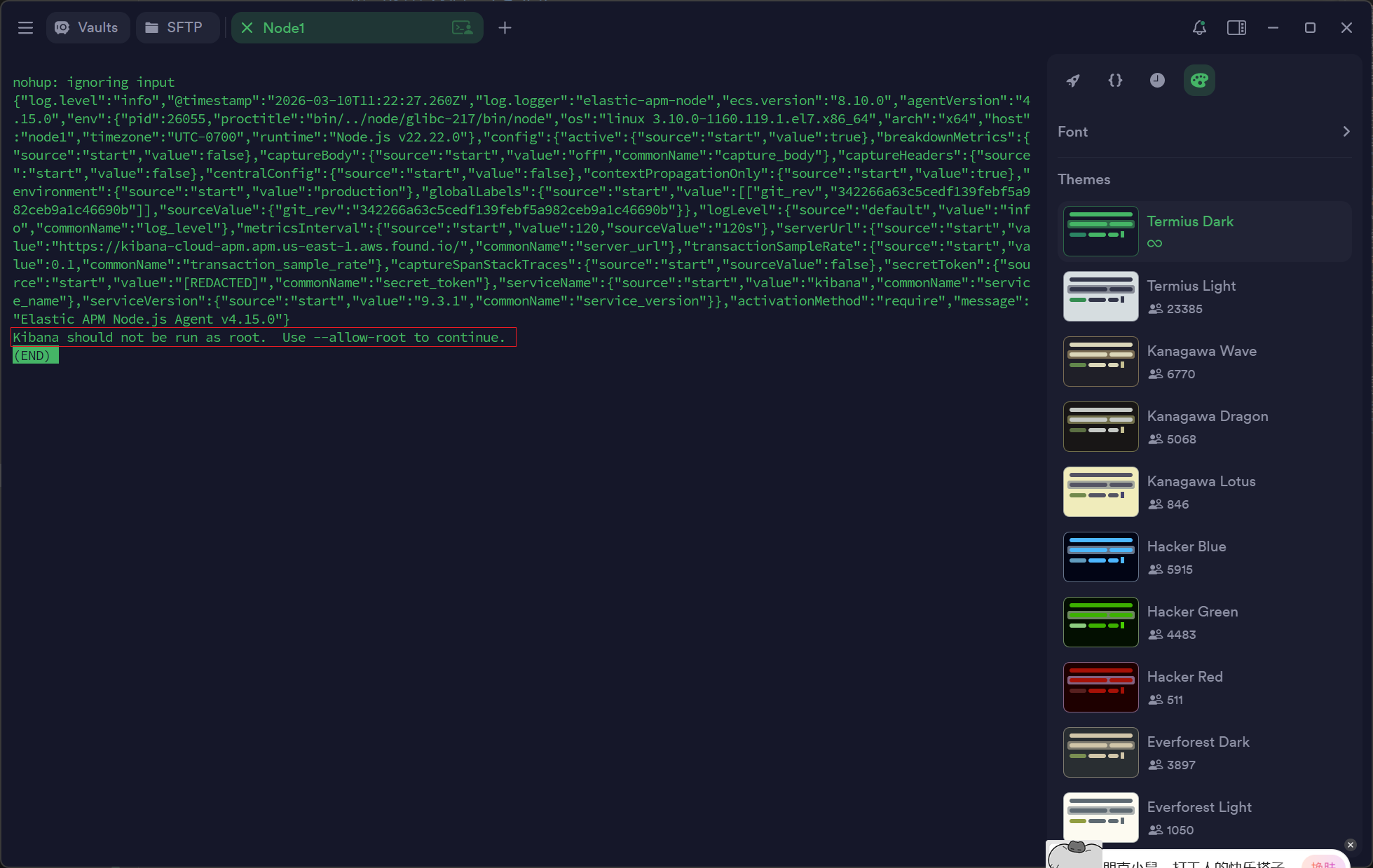
解决方案
- 为 kibana 创建用户
adduser kibana
passwd kibana- 将 kibana 安装包的所有者和组更改为 kibana 用户
注意
如果在 root 下解压了 kibana 安装包,可以通过如下命令将 kibana 安装包的所有者和组更改为 kibana 用户
# 在 root 用户下操作
cd /opt/software
chown -R kibana:kibana kibana-8.14.3Windows 无法访问 Kibana 客户端
原因分析
虚拟机 Linux 系统的防火墙未开放 Kibana 核心端口,导致网络请求被拦截。
解决方案一:开放 Linux 防火墙端口(推荐)
Kibana 核心端口列表:
5601(TCP)- 浏览器访问的 Http 协议 Restful 端口
# 开放核心端口
firewall-cmd --permanent --add-port=5601/tcp
# 重新加载防火墙配置使修改生效
firewall-cmd --reload
# 验证端口是否开放成功
firewall-cmd --list-ports解决方案二:临时关闭防火墙(测试环境可选)
# CentOS/RHEL 系统
systemctl stop firewalld
systemctl disable firewalld
# Ubuntu/Debian 系统
ufw disable# Ubuntu/Debian 系统
ufw disable中文分词器插件安装
在线安装
# analysis-ik 版本号需与 elasticsearch 服务(安装包)版本号一致
bin/elasticsearch-plugin install https://get.infini.cloud/elasticsearch/analysis-ik/8.14.3注意
注意:插件安装完成后, 需重启 elasticsearch 服务才能生效。
离线安装
常用 Query DSL 语法详解
match all 所有匹配
match all是 Elasticsearch 中最基础、最高效的查询类型之一。它会返回索引中的所有文档(不进行任何文本分析或相关性评分,默认情况下,所有匹配的文档其相关性得分 _score 均为 1.0),是获取全量数据或作为其它查询“容器”的理想选择。
POST /{index_name}/_search
{
"query": {
"match_all":{}
}
}term 单值精确匹配
term是 Elasticsearch 中用于精确匹配字段值的核心查询类型。它不进行文本分析(分词),直接在倒排索引中查找指定的确定词条(term)。
term 查询:用于查找包含单个精确词条的文档。它针对一个字段,查询一个特定的值。查询的字段类型可以是普通的单值字段,也可以是数组。
POST /{index_name}/_search
{
"query": {
"term":{
"{field_name}": "{value}"
}
}
}term 适用查询字段
term 查询适用于 keyword、constant_keyword、ip、date 等非分析字段。
term 使用注意事项
避免在 text 类型的字段上使用 term 查询,因为 text 字段会被分词,这样做既没有意义,还很有可能什么也查询不到。
terms 多值精确匹配
terms查询是 Elasticsearch 中用于精确匹配多个值的核心查询类型。它是 term 查询的“复数版”,用于查找包含一个或多个精确词条的文档。它针对一个字段,查询多个值(一个数组),只要文档匹配上任意一个值就会被返回(即 OR 逻辑)。查询的字段类型可以是普通的单值字段,也可以是数组。
POST /{index_name}/_search
{
"query": {
"terms":{
"{field_name}": "[{value1}, {value2}, ...]"
}
}
}range 范围查询
range查询是 Elasticsearch 中用于数值、日期或时间范围字段的核心查询类型。它允许查找某个字段的值落在指定区间内的所有文档。
注意
range 查询不适用于 text 字段
数值范围查询
POST /<index_name>/_search
{
"query": {
"range": {
"{field_name}": {
"gte": <lower_bound>,
"lte": <upper_bound>,
"gt": <greater_than_bound>,
"lt": <less_than_bound>
}
}
}
}POST /employee/_search
{
"query":{
"range":{
"age":{
"gte":25,
"lte":28
}
}
}
}<index_name> 是你想要查询的索引名称。
<field_name> 是你想要对其执行range查询的字段名。
gte 表示大于或等于(Greater Than or Equal)。
lte 表示小于或等于(Less Than or Equal)。
gt 表示严格大于(Greater Than)。
lt 表示严格小于(Less Than)。
<lower_bound>, <upper_bound>, <greater_than_bound>, <less_than_bound> 是指定的数值边界。
日期范围查询
PUT /notes
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"title": {
"type": "text"
},
"content": {
"type": "text"
},
"created_at": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
}
}
}
}POST /notes/_bulk
{"index":{"_id":"1"}}
{"title":"Note 1","content":"This is the first note.","created_at":"2025-07-01 12:00:00"}
{"index":{"_id":"2"}}
{"title":"Note 2","content":"This is the second note.","created_at":"2025-07-05 15:30:00"}
{"index":{"_id":"3"}}
{"title":"Note 3","content":"This is the third note.","created_at":"2025-07-10 08:45:00"}
{"index":{"_id":"4"}}
{"title":"Note 4","content":"This is the fourth note.","created_at":"2025-07-15 20:15:00"}POST /notes/_search
{
"query": {
"range": {
"created_at": {
"gte": "2025-07-05 00:00:00",
"lte": "2025-07-10 23:59:59"
}
}
}
}POST /notes/_search
{
"query": {
"range": {
"created_at": {
"lte": "now-36w"
}
}
}
}Elasticsearch 支持日期数学表达式,允许在查询和聚合中使用相对时间点。
| 时间表达式 | 对应时间点 |
|---|---|
now | 当前时间点 |
now-1d | 从当前时间点向前推进1天的时间点 |
now-1w | 从当前时间点向前推进1周的时间点 |
now-1M | 从当前时间点向前推进1个月的时间点 |
now-1y | 从当前时间点向前推进1年的时间点 |
now+1h | 从当前时间点向后推进1小时的时间点 |
exists 非空查询
exists查询是 Elasticsearch 中用于检查某个字段是否存在(非空)的查询类型。它不关心字段值是什么,只关心该字段是否在文档中存在且有有效内容。
重要提示
- 字段必须是非空值才视为“存在”。
- 空字符串
""、null、[](空数组)、{}(空对象)都算不存在。
POST /<index_name>/_search
{
"query": {
"exists": {
"field": "<field_name>"
}
}
}ids 查询
ids查询是 Elasticsearch 中用于根据文档的 _id 精确查找指定文档的核心查询类型。它不进行任何分析或评分计算,直接通过 _id 在倒排索引中定位文档。
POST /<index_name>/_search
{
"query":{
"ids":{
"values":["<id1>", "<id2>", ...]
}
}
}prefix 前缀匹配
prefix查询是 Elasticsearch 中用于查找以指定前缀开头的词条的核心查询类型。它不会进行全文分析,而是直接在倒排索引中查找所有以该前缀开始的词条。
强烈建议
prefix 查询方式仅适用于关键字类型(keyword)的字段。
POST /<index_name>/_search
{
"query":{
"prefix":{
"<field_name>":"<prefix_value>"
}
}
}wildcard 通配符匹配
wildcard查询是 Elasticsearch 中用于基于通配符模式进行模糊匹配的查询类型。它支持两个通配符:
*:匹配零个或多个字符?:匹配单个任意字符
| 符号 | 含义 | 示例 |
|---|---|---|
* | 匹配零个或多个字符 | "elasti*" → 匹配 Elasticsearch, Elastic, Elastica |
? | 匹配单个任意字符 | "report?.txt" → 匹配 report1.txt, reportA.txt |
注意
text 字段默认分词器会转小写。
比如 text 类型的“Java编程思想”,分词后会分为 ["java", "编程", "思想"]。
使用 “Java*” 查询不到,但使用 “java*” 时可以查询到。
危险
以*开头的查询(如*abc)会扫描所有文档,性能极差!建议避免在生产环境滥用!!!
{
"query":{
"wildcard":{
"<field_name>":"<pattern>"
}
}
}regexp 正则匹配查询
regexp查询是 Elasticsearch 中用于基于正则表达式进行模式匹配的查询类型。它支持完整的正则表达式语法,可以实现极其复杂的字符串匹配逻辑。
| 匹配符 | 作用 | 示例 | 释义 | 备注 |
|---|---|---|---|---|
. | 匹配任意单个字符(除换行符 \n 外) | a.c | 匹配 abc, a1c, a c 等 | 默认不匹配换行符;部分引擎支持 s 标志使其匹配换行符 |
^ | 匹配字符串开头 | ^hello | 只匹配以 hello 开头的字符串 | 锚点;在多行模式(如 re.MULTILINE)下也匹配行首 |
$ | 匹配字符串结尾 | world$ | 只匹配以 world 结尾的字符串 | 锚点;在多行模式下也匹配行尾 |
* | 匹配前一个字符 0 次或多次 | a* | 匹配 "", "a", "aa", "aaa" | 贪婪匹配(尽可能多),后加 ? 变为非贪婪(*?) |
+ | 匹配前一个字符 1 次或多次 | a+ | 匹配 "a", "aa", "aaa" | 贪婪匹配,不能匹配空串;后加 ? 变为非贪婪(+?) |
? | 匹配前一个字符 0 次或 1 次 | a? | 匹配 "" 或 "a" | 贪婪匹配(优先匹配1次),后加 ? 变为非贪婪(??) |
{n} | 匹配前一个字符恰好 n 次 | a{3} | 只匹配 "aaa" | n 必须 ≥ 0;固定次数,无贪婪/非贪婪区别 |
{n,} | 匹配前一个字符至少 n 次 | a{2,} | 匹配 "aa", "aaa", "aaaa" | 贪婪匹配,后加 ? 变为非贪婪({n,}?) |
{n,m} | 匹配前一个字符 n 到 m 次 | a{2,4} | 匹配 "aa", "aaa", "aaaa" | 贪婪匹配,后加 ? 变为非贪婪({n,m}?);需满足 m ≥ n ≥ 0 |
[] | 匹配方括号内的任意一个字符 | [abc] | 匹配 "a", "b", "c" | 可用范围如 [a-z];特殊字符(如 ^, -, ])在括号内有特殊含义,需注意放置位置或转义 |
[^] | 匹配不在方括号内的任意一个字符 | [^abc] | 匹配非 a, b, c 的字符 | 脱字符 ^ 在开头表示否定;其余位置表示字面 ^ |
- | 表示范围(在 [] 内) | [a-z] | 匹配任意小写字母 | 在字符集中间时表示范围;若要匹配字面 -,可放在开头、结尾或转义 |
| ` | ` | 或操作(逻辑或) | `cat | dog` |
() | 分组(捕获组) | (ab)+ | 匹配 "ab", "abab" 并捕获内容 | 捕获组会保存匹配的子串,可通过反向引用等使用 |
(?:...) | 非捕获分组 | (?:ab)+ | 匹配 "ab" 重复,但不捕获内容 | 仅用于分组,不保存匹配内容,提高性能或避免干扰捕获 |
\ | 转义字符 | \. | 匹配字面点号 . | 用于取消元字符的特殊含义,或表示特殊转义序列(如 \n) |
\d | 匹配数字(0-9) | \d{3} | 匹配三个数字,如 "123" | 等价于 [0-9];部分引擎支持 Unicode 数字 |
\D | 匹配非数字 | \D+ | 匹配非数字字符序列,如 "abc" | 等价于 [^0-9] |
\w | 匹配单词字符(字母、数字、下划线) | \w+ | 匹配 "hello", "user_123" | 等价于 [a-zA-Z0-9_];部分引擎支持 Unicode 字母/数字 |
\W | 匹配非单词字符 | \W | 匹配空格、标点符号等,如 " "、"," | 等价于 [^a-zA-Z0-9_] |
\s | 匹配空白字符(空格、制表符、换行等) | \s+ | 匹配多个空格 | 包括 \t, \n, \r, \f, \v 等 |
\S | 匹配非空白字符 | \S+ | 匹配非空白内容,如 "hello" | 等价于 [^\s] |
\b | 单词边界 | \bcat\b | 匹配独立的 "cat",不匹配 "category" | 位置锚点,不消耗字符;在字符类 [] 中表示退格符 |
\B | 非单词边界 | \Bcat\B | 匹配 cat 出现在其他字符中间,如 "category" | 与 \b 相反,也是位置锚点 |
(?=...) | 正向先行断言 | test(?=ing) | 匹配后跟 "ing" 的 "test" | 前瞻条件,不消耗字符(不将 "ing" 纳入匹配结果) |
(?!...) | 负向先行断言 | test(?!ing) | 匹配不后跟 "ing" 的 "test" | 同上,条件为后面不跟随指定模式 |
(?<=...) | 正向后行断言 | (?<=pre)fix | 匹配前面有 "pre" 的 "fix" | 后顾条件,不消耗字符;部分引擎要求子表达式长度固定 |
(?<!...) | 负向后行断言 | (?<!pre)fix | 匹配前面没有 "pre" 的 "fix" | 同上,条件为前面不出现指定模式 |
{
"query":{
"regexp":{
"<field_name>":"<regex_pattern>"
}
}
}POST /{index_name}/_search
{
"query":{
"regexp":{
"name":"^张.*"
}
}
}POST /{index_name}/_search
{
"query": {
"regexp": {
"phone": "^1[3-9]\\d{9}$"
}
}
}POST /{index_name}/_search
{
"query": {
"regexp": {
"email": "^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}$"
}
}
}建议
强烈建议:对需要 regexp 匹配的字段使用 keyword 映射。
注意
对于 text 类型,仅当字段被分析后能生成对应词条时才有效。